Evolution of data management technology
Computers can now store all forms of information: records, documents, images, sound recordings, videos, scientific data, and many new data formats. Society has made great strides in capturing, storing, managing, analyzing, and visualizing this data. These tasks are generically called data management. This article sketches the evolution of data management systems. There have been six distinct phases in data management. Initially, data was manually processed. The next step used punched-card equipment and electromechanical machines to sort and tabulate millions of records. The third phase stored data on magnetic tape and used stored-program computers to perform batch processing on sequential files. The fourth phase introduced the concept of a database schema and on-line navigational access to the data. The fifth step automated access to relational databases and added distributed and client server processing. We are now in the early stages of sixth-generation systems that store richer data types, notably documents, images, voice, and video data. These sixth-generation systems are the storage engines for the emerging Internet and intranets.
Early data management systems automated traditional information processing. Today they allow fast, reliable, and secure access to globally distributed data. Tomorrow's systems will access and summarize richer forms of data. It is argued that multimedia databases will be a cornerstone of cyberspace.

Traditional approaches to master data management The enterprise application Traditional approaches to master data include the use of existing enterprise applications, data warehouses and even middleware. Some organizations approach the master data issue by leveraging dominant and seemingly domain-centric applications, such as a customer relationship management (CRM) application for the customer domain or an enterprise resource planning (ERP) application for the product domain. However, CRM and ERP, among other enterprise applications, have been designed and implemented to automate specific business processes such as customer on-boarding, procure-to-pay and order-to-cash—not to manage data across these processes. The result is that a specific data domain, such as customer or product, may actually reside within multiple processes, and therefore multiple applications.
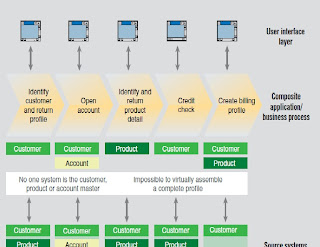
In this scenario using application masters, it is difficult to determine which iteration of customer, product or account—if any—is complete and correct. Additional complexity occurs as organizations attempt to maintain the correct copy of the data, and identify and understand all of the systems that can update a particular domain, those that consume portions of the updates, and the frequency rate at which this consumption occurs. It quickly becomes apparent to organizations that have undergone such a project that the process-automating application cannot also manage data across the enterprise.
The data warehouse Alternately, some enterprise initiatives have attempted to repurpose new or existing data warehouses to serve as a master data repository. As data warehouses aggregate enterprise information, the warehouse is often viewed as a starting point for companies attempting to master their data. However, data warehouses have inherent design characteristics to optimize reporting and analysis, and to drive sophisticated insight to the business. This design, while effective for its primary use, cannot scale well within an operational environment—even in the case of dynamic warehousing—when measured against the needs of most businesses today. Based on its fundamental design, the data warehouse also lacks data management capabilities. Essential functionality such as operational business services, collaborative workflows and real-time analytics that are critical to success in these types of master data implementations require large amounts of custom coding. Similarly, data management capabilities—data changes that trigger events and intelligent understanding of unique views required by consuming systems—are also absent from a data warehouse.
Integration middleware Enterprise information integration (EII) or enterprise application integration (EAI) technologies used to federate and synchronize systems and data have also been presented as substitutes for data management products. Although these solutions can tie together disparate pieces of architecture either at the data tier (EII) or at the application tier (EAI), they do not provide either a physical or virtual repository to manage these key data elements. And much like warehouses, they lack data functionality. The management of data processes poses yet another challenge. Choosing to build functionality within this middleware technology can affect performance in its core competency: the integration of applications and data. Without a true master data solution to complement it, the implementation of EII and EAI technology can actually add to the architectural complexity of the business and perpetuate master data problems with point-to-point integration. In most cases, these methods fail because they are designed to treat data symptoms, such as fragmented data or systems that are out of sync, not the root cause of the master data problem. That root cause is that data is tightly coupled to applications and business processes and this data is not being managed by a single, independent resource that can capture the complete and current enterprise understanding of the domain(customer,product, account or supplier).
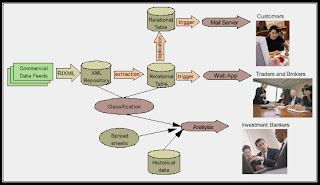
While EII and EAI technologies specialize in specific functions such as data federation, data quality or aggregate analytics, they do not manage the essential data processes or data changes that can initiate other processes such as quality and data stewardship. Attempting to manage these data processes virtually can mean that an essential fact—like the correct address of a customer—must be determined one very transaction; for example, determining whether address 1 from system A or address 2 from system B is correct. It is also necessary to persist this information because the data is created and changed over time— this time frame is known as the information life cycle—to capture net new data like privacy preferences and to deliver this information in context to all of the relevant consumers, typically on demand via business services.
The problem with traditional approaches
The following example illustrates the problem. A customer contact occurs in the call center. This action initiates an address change to a customer record. The address change is immediately reflected in the CRM application, but the billing system is not updated. The customer’s bill for that month is sent to the wrong address and the analytics are skewed because the data warehouse did not receive the required change. The ERP system, on the other hand, has a third address, confusing data stewards and forcing another customer contact to try to correct the error. The result is a poor customer service experience for the customer. No single application has the ability to manage the “golden copy” of this customer information to ensure all systems receive the necessary changes, as well as triggering duplicate suspect processing (matching the customer with an already existing address), event handling (such as alerting a data steward to the problem) and analyzing whether a product offer should be made due to the change. While existing systems are automating their associated business processes, this dynamic data is actually driving process changes of its own. Integration technology or a data warehouse in combination with extensive customization may provide the ability to link some of these applications and data elements. But does this integration occur frequently enough to avoid discrepancies across the enterprise? What if the address change was originally made to the billing system when the customer received the last invoice statement? Will this information be overwritten by the dated CRM address? What happens with the addition of another channel such as a self-service Web application that also has an address update capability?

The evolution of master data management solutions
In general, master data management (MDM) solutions should offer the following:
• Consolidate data locked within the native systems and applications
• Manage common data and common data processes independently with functionality for use in business processes
• Trigger business processes that originate from data change
• Provide a single understanding of the domain—customer, product, account, location— for the enterprise
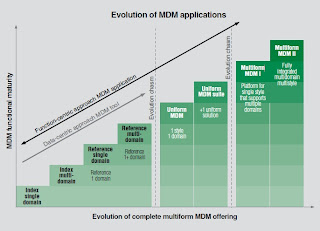
MDM products, however, address these four requirements very differently. Some products decouple data linked to source systems so they can dynamically create a virtual view of the domain, while others include the additional ability to physically store master data and persist and propagate this information. Some products are not designed for a specific usage style, while others provide a single usage of this master data. Even more mature products provide all of the usage types required in today’s complex business—collaborative, operational and analytic—as out-of-the-box functionality. These mature products also provide intelligent data management by recognizing changes in the information and triggering additional processes as necessary. Finally, MDM products vary in their domain coverage, ranging from specializing in a single domain such as customer or product to spanning multiple and integrated domains. Those that span multiple domains help to harness not only the value of the domain, but also the value between domains, also known as relationships. Relationships may include customers to their locations, to their accounts or to products they have purchased. This combination of multiple domains, multiple usage styles and the full set of capabilities between creating a virtual view and performance in a transactional environment is known as multiform master data management. Figure 2 depicts these different solutions and their placement in functional maturity versus MDM evolutionary stages.
Ref:
1. From Data Management to Information Integration: A Natural Evolution
Mary Roth, Senior engineer and Manager , IBM Silicon Valley Lab
2. IBM Multiform Master Data Management: The evolution of MDM applications.
http://www.itworldcanada.com/WhitePaperLibrary/PdfDownloads/IBM-LI-Evolution_of_MDM.pdf
Computers can now store all forms of information: records, documents, images, sound recordings, videos, scientific data, and many new data formats. Society has made great strides in capturing, storing, managing, analyzing, and visualizing this data. These tasks are generically called data management. This article sketches the evolution of data management systems. There have been six distinct phases in data management. Initially, data was manually processed. The next step used punched-card equipment and electromechanical machines to sort and tabulate millions of records. The third phase stored data on magnetic tape and used stored-program computers to perform batch processing on sequential files. The fourth phase introduced the concept of a database schema and on-line navigational access to the data. The fifth step automated access to relational databases and added distributed and client server processing. We are now in the early stages of sixth-generation systems that store richer data types, notably documents, images, voice, and video data. These sixth-generation systems are the storage engines for the emerging Internet and intranets.
Early data management systems automated traditional information processing. Today they allow fast, reliable, and secure access to globally distributed data. Tomorrow's systems will access and summarize richer forms of data. It is argued that multimedia databases will be a cornerstone of cyberspace.

Traditional approaches to master data management The enterprise application Traditional approaches to master data include the use of existing enterprise applications, data warehouses and even middleware. Some organizations approach the master data issue by leveraging dominant and seemingly domain-centric applications, such as a customer relationship management (CRM) application for the customer domain or an enterprise resource planning (ERP) application for the product domain. However, CRM and ERP, among other enterprise applications, have been designed and implemented to automate specific business processes such as customer on-boarding, procure-to-pay and order-to-cash—not to manage data across these processes. The result is that a specific data domain, such as customer or product, may actually reside within multiple processes, and therefore multiple applications.
In this scenario using application masters, it is difficult to determine which iteration of customer, product or account—if any—is complete and correct. Additional complexity occurs as organizations attempt to maintain the correct copy of the data, and identify and understand all of the systems that can update a particular domain, those that consume portions of the updates, and the frequency rate at which this consumption occurs. It quickly becomes apparent to organizations that have undergone such a project that the process-automating application cannot also manage data across the enterprise.

The data warehouse Alternately, some enterprise initiatives have attempted to repurpose new or existing data warehouses to serve as a master data repository. As data warehouses aggregate enterprise information, the warehouse is often viewed as a starting point for companies attempting to master their data. However, data warehouses have inherent design characteristics to optimize reporting and analysis, and to drive sophisticated insight to the business. This design, while effective for its primary use, cannot scale well within an operational environment—even in the case of dynamic warehousing—when measured against the needs of most businesses today. Based on its fundamental design, the data warehouse also lacks data management capabilities. Essential functionality such as operational business services, collaborative workflows and real-time analytics that are critical to success in these types of master data implementations require large amounts of custom coding. Similarly, data management capabilities—data changes that trigger events and intelligent understanding of unique views required by consuming systems—are also absent from a data warehouse.
Integration middleware Enterprise information integration (EII) or enterprise application integration (EAI) technologies used to federate and synchronize systems and data have also been presented as substitutes for data management products. Although these solutions can tie together disparate pieces of architecture either at the data tier (EII) or at the application tier (EAI), they do not provide either a physical or virtual repository to manage these key data elements. And much like warehouses, they lack data functionality. The management of data processes poses yet another challenge. Choosing to build functionality within this middleware technology can affect performance in its core competency: the integration of applications and data. Without a true master data solution to complement it, the implementation of EII and EAI technology can actually add to the architectural complexity of the business and perpetuate master data problems with point-to-point integration. In most cases, these methods fail because they are designed to treat data symptoms, such as fragmented data or systems that are out of sync, not the root cause of the master data problem. That root cause is that data is tightly coupled to applications and business processes and this data is not being managed by a single, independent resource that can capture the complete and current enterprise understanding of the domain(customer,product, account or supplier).

While EII and EAI technologies specialize in specific functions such as data federation, data quality or aggregate analytics, they do not manage the essential data processes or data changes that can initiate other processes such as quality and data stewardship. Attempting to manage these data processes virtually can mean that an essential fact—like the correct address of a customer—must be determined one very transaction; for example, determining whether address 1 from system A or address 2 from system B is correct. It is also necessary to persist this information because the data is created and changed over time— this time frame is known as the information life cycle—to capture net new data like privacy preferences and to deliver this information in context to all of the relevant consumers, typically on demand via business services.
The problem with traditional approaches
The following example illustrates the problem. A customer contact occurs in the call center. This action initiates an address change to a customer record. The address change is immediately reflected in the CRM application, but the billing system is not updated. The customer’s bill for that month is sent to the wrong address and the analytics are skewed because the data warehouse did not receive the required change. The ERP system, on the other hand, has a third address, confusing data stewards and forcing another customer contact to try to correct the error. The result is a poor customer service experience for the customer. No single application has the ability to manage the “golden copy” of this customer information to ensure all systems receive the necessary changes, as well as triggering duplicate suspect processing (matching the customer with an already existing address), event handling (such as alerting a data steward to the problem) and analyzing whether a product offer should be made due to the change. While existing systems are automating their associated business processes, this dynamic data is actually driving process changes of its own. Integration technology or a data warehouse in combination with extensive customization may provide the ability to link some of these applications and data elements. But does this integration occur frequently enough to avoid discrepancies across the enterprise? What if the address change was originally made to the billing system when the customer received the last invoice statement? Will this information be overwritten by the dated CRM address? What happens with the addition of another channel such as a self-service Web application that also has an address update capability?

The evolution of master data management solutions
In general, master data management (MDM) solutions should offer the following:
• Consolidate data locked within the native systems and applications
• Manage common data and common data processes independently with functionality for use in business processes
• Trigger business processes that originate from data change
• Provide a single understanding of the domain—customer, product, account, location— for the enterprise
MDM products, however, address these four requirements very differently. Some products decouple data linked to source systems so they can dynamically create a virtual view of the domain, while others include the additional ability to physically store master data and persist and propagate this information. Some products are not designed for a specific usage style, while others provide a single usage of this master data. Even more mature products provide all of the usage types required in today’s complex business—collaborative, operational and analytic—as out-of-the-box functionality. These mature products also provide intelligent data management by recognizing changes in the information and triggering additional processes as necessary. Finally, MDM products vary in their domain coverage, ranging from specializing in a single domain such as customer or product to spanning multiple and integrated domains. Those that span multiple domains help to harness not only the value of the domain, but also the value between domains, also known as relationships. Relationships may include customers to their locations, to their accounts or to products they have purchased. This combination of multiple domains, multiple usage styles and the full set of capabilities between creating a virtual view and performance in a transactional environment is known as multiform master data management. Figure 2 depicts these different solutions and their placement in functional maturity versus MDM evolutionary stages.

Ref:
1. From Data Management to Information Integration: A Natural Evolution
Mary Roth, Senior engineer and Manager , IBM Silicon Valley Lab
2. IBM Multiform Master Data Management: The evolution of MDM applications.
http://www.itworldcanada.com/WhitePaperLibrary/PdfDownloads/IBM-LI-Evolution_of_MDM.pdf
No comments:
Post a Comment